



Kilka dni temu (dokładnie 28 lipca 2015 roku) w Search Console (dawniej GWT), wielu pozycjonerów i administratorów stron mogło zauważyć dziwny komunikat wysłany przez Google. Jego treść możecie zobaczyć na poniższym screenie:
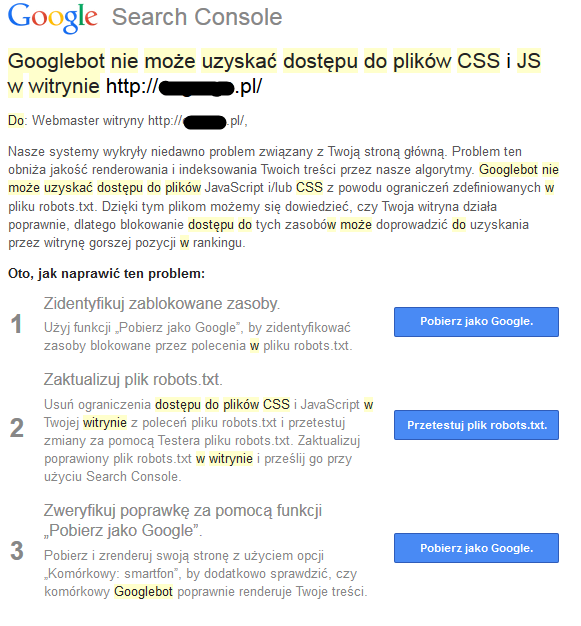
Jak podaje komunikat, Googlebot ma problem z dostępem do zasobów CSS i JSS, które odpowiedzialne są za treść oraz wygląd strony. Komunikat dotyczył strony zbudowanej na CMS WordPress, jednak jak się później okazało, wielu innych pozycjonerów otrzymało komunikaty także dla stron zbudowanych na innych skryptach (Joomla, Presta i wiele więcej).
Postanowiliśmy sprawdzić, czy dany komunikat jest faktycznie tak groźny, jak sugeruje Google. Pobraliśmy przykładową stronę oczami Googlebot’a. Okazało się, że winowajcą całego zamieszania jest plik robots, który blokował dla robotów dostęp do katalogu z plikami CSS i JSS motywu WordPress (standardowy zapis skryptu WordPress w pliku robots ” Disallow: /wp-admin/”). Dla testów usnęliśmy ten wpis z pliku robots i ponownie pobraliśmy stronę jako robot. Problem zniknął a robot wygenerował taki sam widok, jak w przypadku witryny dostępnej dla użytkownika.
Panda 4.2 atakuje?
Wiele osób spekuluje, że komunikaty zostały wysłane na ślepo (w wielu przypadkach strona nie blokowała dostępu do zasobów CSS, a mimo to webmaster otrzymywał komunikat). Istnieją też teorie, że rzeczone komunikaty to sprawka aktualizacji Panda 4.2, o której pisaliśmy w poprzednim wpisie (TUTAJ LINK DO WPISU O PANDA 4.2). Google jak na razie ostrzega, jednak nie wiadomo, czy blokowanie zasobów nie zostanie uznawane przez Pandę jako chęć ukrycia treści przed robotem, co może skutkować obniżeniem pozycji w wyszukiwarkach.
Google nie powinno wymuszać na uzyszkodnikach dostępu do tych plików. Ze względów bezpieczeństwa dostęp do tych plików powinien mieć jedynie użytkownik serwera na jakim wykonywany jest skrypt odpowiedzialny za wyświetlanie strony. Po co Google i innym dostęp do tych plików? Ich powinna jedynie interesować wygenerowana strona. To, że Google próbuje wymusić dostęp do tych plików gdyż chce mieć prostą możliwość analizy ich pod kontem tego, czy nie zostało w nich zaszyte coś co może wpłynąć na oszukanie ich algorytmów (jak np. tekst po za ekranem w css,, czy jakiś cloaking w javie, to jedno, ale my nie musimy się przecież godzić na to abyśmy mieli gorzej, po to aby oni mili lepiej 🙂
My się nie musimy na to godzić, tak samo jak nie musimy korzystać z Google 😉 Idąc np. na basen też stosujesz się do panujących zasad a jak się nie stosujesz to Cię wypraszają – tak samo jest tutaj 😉
WordPress czy joomla mają wiele modułów/widgetów które ładują pliki css i js z podkatalogów innych niż szablon i często są one domyślnie blokowane przez robots.txt. Teoretycznie każda strona powinna działać bez plików css i js i powinna prezentować pełnię treści, powinno to googlowi wystarczyć. Ale czasy stron w czystym html-u minęły już bardzo dawno i js oraz css stanowi integralną część strony dlatego nie powinno nas dziwić że także google oczekuje dostępu do tych bibliotek.
Nie sądzę aby były z tym związane kary jednak poprawiłem dostępy dla wszystkich stron które otrzymały powiadomienia. Nie ma powodu aby zabraniać robotom pobierania js i css. Brak możliwości odtworzenia pełnej struktury strony przez google-a nie pozwala np. sprawdzić jak strona poradzi sobie na urządzeniu mobilnym a wiemy że google ostatnio rozwija ten temat znacząco co mogło pociągnąć za sobą właśnie serię tych ostrzeżeń.